Separating Perception and Reasoning via Relation Networks
Visual Question Answering (VQA) is a multi-modal task relating text and images through captions or a questionnaire. For example, with a picture of a busy highway, there could be a question: “How many red cars are there?” or “Are there more motorbikes than cars?”. It is a very challenging task since it requires high-level understanding of both the text and the image and the relationships between them.
In this project, we study the Relation Networks implementations of AI approaches that offer the ability to combine neural and symbolic representations to answer VQA task.
Relation Network
Relation Network is a neural network that works best for relational reasoning. The design philosophy behind RNs is to constrain the functional form of a neural network so that it captures the core common properties of relational reasoning.
The simplest form of RN composite function is: $RN(O) = f_ϕ(Σ_{i,j}g_θ(o_i, o_j))$ where,
- the input is a set of “objects” $O = {o_1, o_2, …, o_n}, o_i ∈ R^m$ is the $i^{th}$ object in an image
- $f_ϕ$ and $g_θ$ are multi-layer perceptrons(MLPs) for the functions with parameters $ϕ$ and $θ$ respectively.
- The role of $g_θ$ is to infer the ways in which two objects are related, or if they are even related at all and $f_ϕ$ is the classifier
Sort-of-CLEVR Dataset
We’ll be using Sort-of-CLEVR dataset for our RN network.
The Sort-of-CLEVR dataset contains 10000 images of size 75 75 3, 200 of which are used as the validation set.
There are 20 questions for each image (10 non-relational and 10 relational).
The non-relational questions are divided into 3 subtypes:
- Query shape, ex: What is the shape of the red object?
- Query horizontal position, ex: Is the red object on the left or right of the image?
- Query vertical position, ex: Iss the red object on the top or bottom of the image?
The relational questions are divided into 3 subtypes:
- Closest to, ex: What is the shape of the object that is closest to the green object?
- Furthest from, ex: What is the shape of the object that is furthest to the green object?
- Count, ex: How many objects have the shape of the green object?
Questions are encoded as binary strings of length 11, where the first 6 bits identify the color of the object mentioned in the question, as a one-hot vector, and the last 5 bits identify the question type and the subtype.
[index_0-5 → one-hot vector of 6 colors,
index_6 → non_rel_ques,
index_7 → rel_ques,
index_8,9,10 → question_subtype]
Answers are represented as a one-hot vector of size 10.
For non-relational questions the answers are of the form:
[index_0,1 → yes, no,
index_2,3 → is rectangle?, is circle?,
index_4-9 → one-hot vector of 6 colors (red, green, blue, orange, gray, yellow)]
For relational questions the answers are of the form:
[index_0,1 → n/a, n/a,
index_2,3 → is rectangle?, is circle?,
index_4-9 → count one-hot vector to denote the number of objects 0, 1, ..., 5]
RN Model Architecture
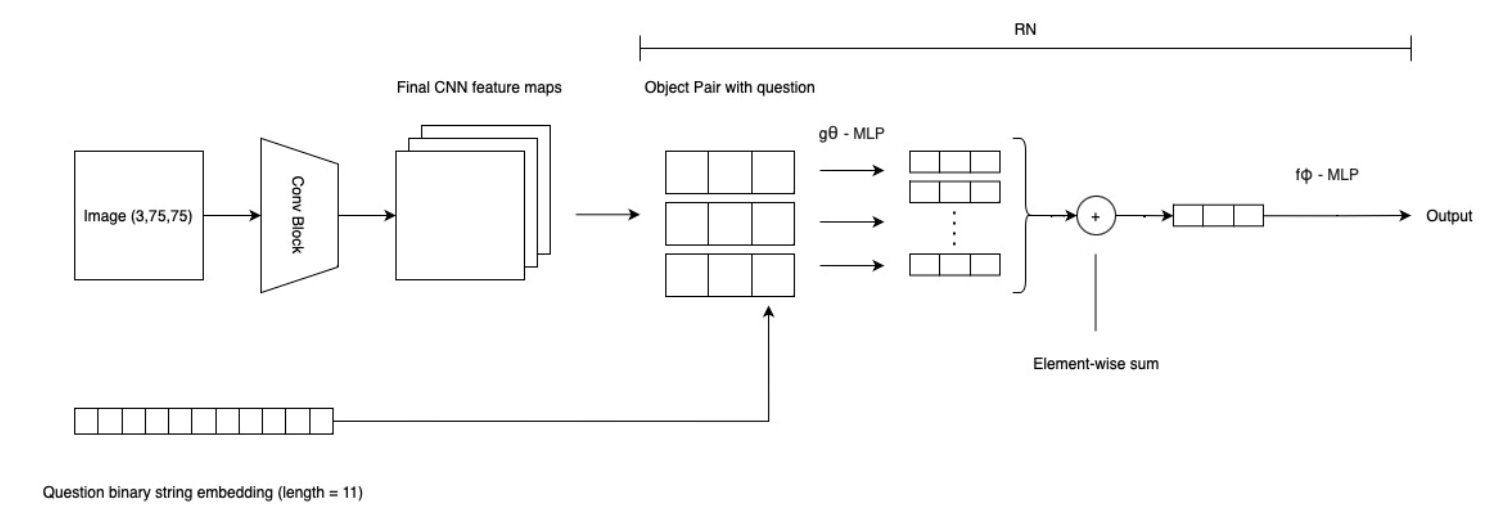
Data flow through the network is as follows:-
-
Image and Question-Answer feature map:
1- Image Feature Maps are generated using 4 convolutional layers with 32, 64, 128, and 256 kernels with ReLU activation and batch-normalization
2- Questions and Answers (labels) are encoded as fixed-length binary strings
-
RN:
3- The questions and the feature maps are passed directly to the RN
4- Object pairs with questions (see detailed explanation below) are generated by concatenating questions to the object pairs generated from the CNN feature maps
5- Add coordinates position information for particle image feature
6- $g_θ$ function: The questions are passed directly to the RN along side the object pairs to a 4 layer MLP consisting of 2000 units per layer with ReLU activation
7- We apply element-wise sum for the output of $g_θ$ to scale back to the original batch size
8- $f_ϕ$ function: The output is passed to a 4 layer MLP consisting of 2000, 1000, 500, and 100 units with ReLU activation
9- The final output linear layer in $f_ϕ$ has a softmax activation over the 10 possible answers (answer is a a one-hot vector of size 10)
Cross entropy loss function with Adam optimizer is used to train the network.
Hyperparameters for the network:
- batch_size = 64
- learning_rate = $1e−4$
Object pairs with questions, for 1 image
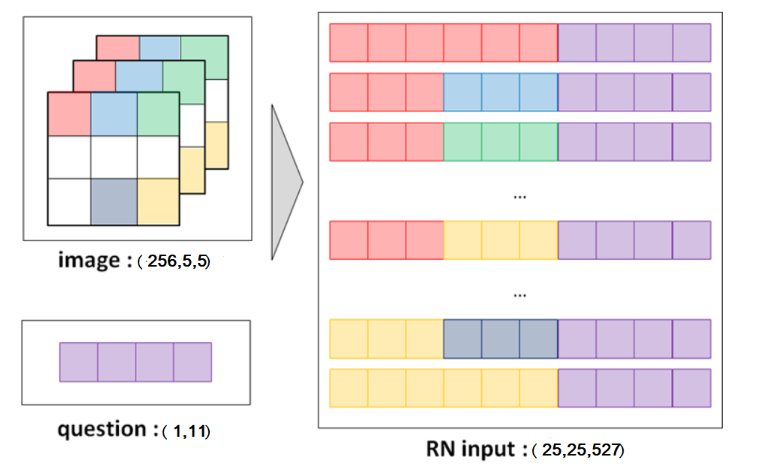
Questions:
-
Each question one-hot vector is of size (1,11)
-
We add two axes and repeat the questions across one axes, making the dimension (25,1,11)
Feature Map:
- The output feature map for each image is of size (256,5,5)
Object pairs with questions:
-
We reshape and add coordinates to the feature map, making the dimension (25, 258)
-
From this, create set 1 and set 2 data
-
Create set 1: add an axis at loc=0 and repeating pixels across rows: (25, 258) -> (1, 25, 258) -> (25,25,258)
-
Create set 2 by adding an axis at loc=1, adding ques of size 11 along that axis and repeating pixels across columns: (25, 258) -> (25, 1, 258) -> (25, 1, 269) -> (25,25,269)
-
Finally, concatenate set 1 and set 2 along the last axes, making the dimension (25,25,527), where
last_dim_size=(2 for each set*(256 features + 2 coordinates)) + 11 ques = 527
Check out the code for detailed description on shapes and data transformation.
VQA on Sort-of-CLEVR
- With the github repository as reference, we developed the model architecture, keeping the model size smaller than the one given in the paper, but changing the question embedding shape to match that in the paper (length 11).
- We tried many different architectures: by changing the number of units and number of layers in both $g_\theta$ and $f_\phi$. We also tried with different hyper-parameters: learning rates like, $0.0001, 0.01, 0.1$, and optimizers like SGD, Adam.
- Best model architecture:
- 4 conv layer block with 24 kernels each with ReLU activation and batch normalization.
- $g_\theta$ consists of 4 fully connected layers with 256 units and ReLU activations.
- $f_\phi$ consists of 4 fully connected layers with 256 units and ReLU activation and an output layer with 10 units with a softmax activation.
- Best hyper-parameters:
- number of epochs: 50
- learning rate: $0.001$
- Optimizer: Adam
- Batch size: 64
Results
After training the model for 50 epochs, the best final metrics are as follows:
Relational Data
| Train Accuracy(%) | Train Loss | Test Accuracy(%) | Test Loss |
|---|---|---|---|
| 98.40 | 0.045 | 91.28 | 0.304 |
Non-Relational Data
| Train Accuracy(%) | Train Loss | Test Accuracy(%) | Test Loss |
|---|---|---|---|
| 99.98 | 0.001 | 99.97 | 0.001 |
Sample test outputs:


Team: Atharva Bhagwat, Harini Appansrinivasan, Abdulqadir Zakir
Here is the link to the repository.